
When working with Microsoft Fabric, it’s essential to understand the different options available for data ingestion. Choosing the right tool can significantly affect your workflow, performance and overall data strategy. In this blog, we’ll explore and compare four popular data ingestion tools (Data Pipeline, Dataflow, Notebook and Eventstream) in Microsoft Fabric and understand when and when not to use them.
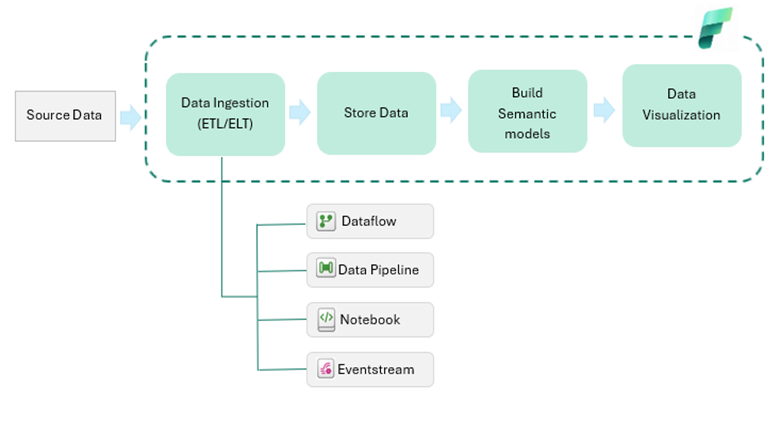
Breakdown of Data Ingestions Tools in Microsoft Fabric
Dataflows
- Access to 150+ connectors to external systems
- Can do Extract, Transform and Load tasks using familiar Power Query interface
- Can access on-premises data
- Ability to upload local files
- Ability to read data in one workspace and load data in another workspace
- Can combine more than one dataset in a dataflow
- Con: Struggles with large datasets, which can be costly if you are transforming loads of data regularly
- Con: Dataflow doesn’t have an OOB data validation ability, although dataflows can be included in data pipelines to tackle error handling.
Data Pipelines
- Primarily an orchestration tool that can also be used to get data into Fabric using Copy Data activity
- Works well with large datasets
- Efficient at importing data from the cloud (e.g., ADLS, Azure SQL)
- Can be used to implement control flow logic
- Can trigger a variety of actions in Fabric:
- Dataflow Gen2
- Notebooks
- Stored Procedures
- KQL script
- Generic webhooks
- Azure Functions
- Azure Databricks
- Azure ML
- Con: Cannot access on-premises data
- Con: Does not have ability to do transformation on its own but can embed Notebooks or Dataflows to perform that task
- Con: Does not work cross-workspace as of now
Notebook
- Can be used to bring data into Fabric via connecting to API’s or client Python libraries
- Can do data validation on incoming data
- Possible con: User needs to have technical knowledge of Python or other Notebook-supporting language
Eventstream
- If you don’t want to do data ingestion, you can create live sync to files and databases that are outside of Fabric.
- For Files: One Lake Shortcuts
- A shortcut enables you to create a live link to data stored in either another part of Fabric (internal shortcut) or in external storage (ADLS, Amazon S3)
- For Tables: Database Mirroring
- Mirroring allows real-time data replication of external databases as delta tables in One Lake
- For Files: One Lake Shortcuts
- No ETL is needed
- Provides near real-time updates to your data
- Merge/update logic is managed automatically
- Con: Works only with a limited selection of data types
Takeaways
Which tool is right for you and your organization? Selecting the right data ingestion tools in Microsoft Fabric is crucial for optimizing your data strategy and workflow. Each tool —Dataflows, Data Pipelines, Notebooks, and Eventstream — offers unique strengths for different business needs. Whether you need robust ETL processes, real-time data updates, or seamless integration with various data sources, Microsoft Fabric provides versatile options to enhance your data management and analytics efforts.
Author: Shriya Dhar | [email protected]
Contact Us
Don’t get lost in the data management shuffle. Contact a member of Withum’s Digital Workplace Solutions Services Team today to get moving in the right direction.



